Product
公開フリーウェア詳細
ODBCアンローダー
ODBCで接続できるデータベースのテーブルから、レコードをテキストに抽出するためのツール
★使用法
ODBCUNL.exe /C:接続先(データソース名)
{/SQL:"select sql文" /S:抽出SQLファイル名 | /T:テーブル名}
[ /U:ログインユーザ名 /P:ログインパスワード ]
[ /O:アンロード先ファイル名 ] (省略時は標準出力)
[{/FIX | /COMMA | /TAB | /SPACE}] 区切り文字指定 (省略時は0x01)
[{/DQ | /SQ}] 文字セパレータ指定 (省略時はなし)
[/H] 項目名出力フラグ (省略時は項目ヘッダ出力なし)
[/E] データ追加フラグ (省略時は上書き)
[/V:nnnn] 処理経過表示敷居値 (省略時は非表示)
* /SQL > /S > /T の順で優先されます.
/FIX = 固定長テキスト
/COMMA = カンマ区切り
/TAB = タブ区切り
/SPACE = 空白区切り
/DQ = 文字列項目をダブルクォーテーションで囲みます
/SQ = 文字列項目をシングルクォーテーションで囲みます
/Eパラメタ指定時はアンロード先ファイルが既に存在したらデータを追加します
* /SパラメタでSQLファイルを指定する場合、その中でシステム日付を使いたい場合
以下のパラメタを指定できます。
%SYSTIME% :システム時刻(HHNNSS)
%SYSDATE% :システム日付(YYYYMMDD)
%SYSDATE+n% :システム日付+n日の日付(YYYYMMDD)
%SYSDATE-n% :システム日付-n日の日付(YYYYMMDD)
戻り値
1:実行時初期化エラー
2:パラメタエラー
3:/Sパラメタに指定されたSQLファイルが存在しない
4:DBコンポーネント初期化エラー
5:SQLがSELECT文以外
6:ログインエラー、DBアクセスエラー
7:ファイルアクセスエラー
9:その他例外エラー
ex1) mydsnというODBCデータソースにusr01/pwd01でログインして、
EMPというテーブルをカンマ区切りで全件、全項目出力。
odbcunl /d:mydsn /u:usr01 /p:pwd01 /o:c:\work\test.csv /t:EMP /COMMA
ex2) mydsnというODBCデータソースにusr01/pwd01でログインして、
query.sqlの実行結果をタブ区切りで出力。
odbcunl /d:mydsn /u:usr01 /p:pwd01 /o:c:\work\test.csv /s:query.sql /TAB
【留意事項】
・利用に際して、接続するDBMS(ORACLEなど)によっては、
クライアントソフトウェアのインストール、環境設定が
必要なものがあります。
事前に接続、動作の確認を行ってからご利用ください。
・/Sオプションで指定されるSQLファイルには1回のSELECT文が記述できます。
終端の";"は不要です。
・BLOBなどテキストで出力するのが難しい(意味がない?)
データ型については処理しません。
対応データ型は、文字列型,数値型,日付型のみです。
・DATE型の項目は "YYYY/MM/DD" 又は "YYYY/MM/DD hh:mm:ss.zzz"
の形式で出力します。
固定長テキストモード時は YYYYMMDD 又は YYYYMMDDhhmmsszzz です。
・テーブルは存在するがデータが無い場合、戻り値は0(正常)となります。
・固定長テキストモードで項目名は出力できません。
・処理経過表示敷居値については、/V:1000 とした場合、1000件毎に
「nnnn/xxxx件目を処理中...」のメッセージが表示されます。
最大値は、1000000です。
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
syslogコマンド&サービスアプリ
バックグラウンドで実行されるバッチや複数のサーバで稼働する処理の実行ログを1サーバで収集することを目的として作成したツール群
★コマンド使用法
syslog.exe /S:ホスト名 /M:メッセージ文字列 [ /P:プロセス名 ]
[ /T:メッセージタイプ ] [ /B ]
[ /EUC | /UTF8 ]
[ /F:送信ログファイル ]
┌──────────────────────────────┐
│/S:ホスト名(nnn.nnnn.nnn.nnn) (必須) │
│/T:メッセージタイプ (省略時="I") │
│ { I (情報) | E (エラー) | W (警告) | C (重要) │
│ A (警報) | N (通知) | M (緊急) | O (その他) } │
│/B (指定時はブロードキャストモード) │
│/EUC (指定時はEUCの2バイト文字でメッセージを送信) │
│/UTF8 (指定時はUTF8の2バイト文字でメッセージを送信) │
│/F:送信ログファイル ※指定時は内容を1行毎に送信 │
└──────────────────────────────┘
例)
syslog /S:svr01 /T:W /M:"警告メッセージ"
syslog /S:192.168.1.10 /T:I /M:"このログが出たらOK"
【留意事項】
・ログを受け取る側のサービスアプリが稼働していなくてもエラーには
なりません。UDPによる通信のための仕様です。注意してください。
・/Pオプションを指定した場合、プロセスIDは送信されません。
逆に、指定しない場合に送信されるプロセスIDは、syslog.exe自身のものです。
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
COBOLデータエディタ
COBOLデータの内容確認や編集を手軽に行うことを目的に作成したツール
富士通系COBOLデータの内容確認や、編集を手軽に行うことを目的に作成しています。 全てのデータ形式に対応できていることを保証するものではありませんが、マルチフォーマット形式にも対応しています。 また、数百MBのデータであっても、画面表示分しかメモリを使わないので、軽く動作することを目指しています。※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
マルチ文字コード変換ツール
文字コードとレコード形式を相互に変換することができるツール
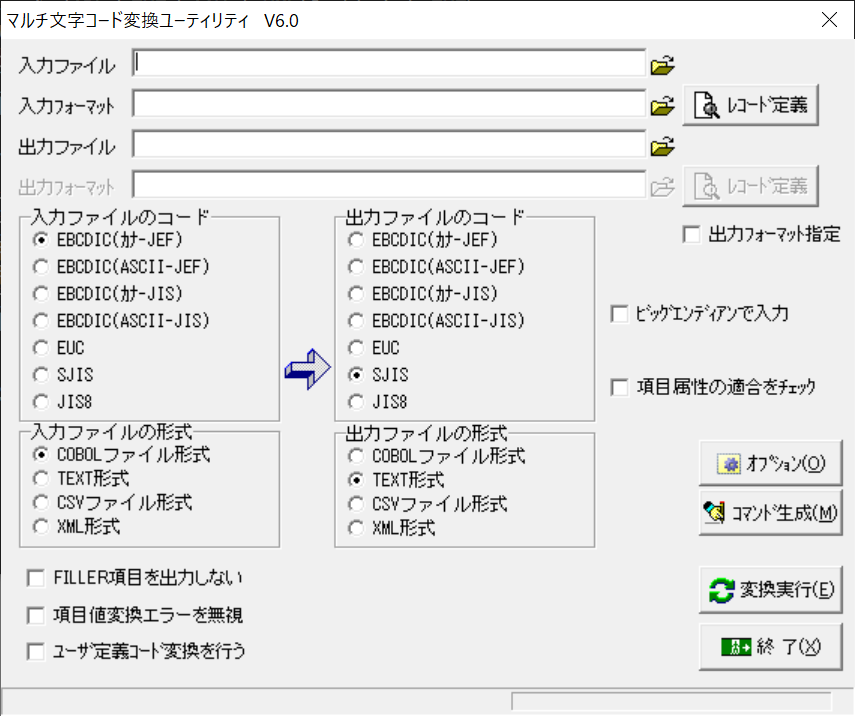
★GUI利用時の画面
・MULTCONV.exeを起動し、入力ファイル、フォーマットファイル(COPY句)、出力ファイル と入力ファイルのコード、出力の形式を指定してください。
★コマンド使用法
MULTCONV.exe /I:変換元ファイル名 /F:フォーマットファイル名
/O:出力先ファイル名 [/F2:出力フォーマットファイル名]
[/IC:入力コード {EBC|EUC|SJ | JS8}] (省略時はEBCとして扱う)
[/OC:出力コード {EBC|EUC|SJ | JS8}] (省略時はSJとして扱う)
[/IT:入力形式 {TXT|CBL|CSV | XML}] (省略時:CBL)
[/OT:出力形式 {TXT|CBL|CSV | XML}] (省略時:TXT)
[/IBE] (入力データのバイナリをビッグエンディアンで扱う)
[/OBE] (出力データのバイナリをビッグエンディアンで扱う)
[/H] [/CD] [/DLM:x] [/TAG:x]|[/DTD] [/B] [/V:nnn]
[/NF] (FILLER項目を出力しない)
[/ES] (項目値変換エラーを無視する)
[/UD] (ユーザ定義コード変換を行う)
※ /H CSV出力時に1レコード目に項目名を出力する
/CD CSV出力時に項目名にデータ型情報を付加
/DLM:x {CSV使用時の区切り文字 comma, tab, space (デフォルト=comma)}
/TAG:x {CSV使用時の文字列引用符 DQ, SQ, none (デフォルト=DQ)}
/DTD XML出力時にDTDファイルを出力
/B CSV,XML出力時にデータから不要な空白を省く
/V:nnn 標準エラー出力に処理中の件数をnnn件毎に表示
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
COBOLデータ差分出力コマンド
2つの富士通系COBOLデータを同じCOPY句で文字コードを合わせて比較し、差分を確認するツール
★コマンド使用法
COBDIFF.exe 比較元ファイル 比較先ファイル /F COPY句ファイル [オプションパラメタ]
戻り値: 0=正常 0<異常
オプションパラメタ
/C1 比較元ファイルの文字コード{SJIS | EBCJEF | EBCJIS | EUC | UTF8} ※省略時はSJIS
/C2 比較先ファイルの文字コード{ C1と同じパラメタパターン } ※省略時は/C1と同じ値
/U ユーザ定義変換テーブルファイル名(富士通 SIMPLIA-TF-MDPORTの定義を流用可能)
/H (16進でもデータの内容を出力する場合指定)
/X (変換エラーがある場合、その項目属性の初期化値で比較する場合指定)
例)COBDIFF.exe TESTDATA.001 TESTDATA.002 /F TESTCOPY.cob /C1 EBCJEF /C2 SJIS
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
ORALE専用アンローダ
ORACLEデータベースのテーブルから、レコードをテキストに抽出するためのツール
★コマンド使用法
Ora2txtR.exe /C:IPアドレス[:ポート]@SID
/U:ログインユーザ名
/P:ログインパスワード
{/SQL:"select sql文" /S:抽出SQLファイル名 | /T:テーブル名}
[ /O:アンロード先ファイル名 ] (省略時は標準出力)
[{/FIX | /COMMA | /TAB | /SPACE}] 区切り文字指定 (省略時は0x01)
[{/DQ | /SQ}] 文字セパレータ指定 (省略時はなし)
[/H] 項目名出力フラグ (省略時は項目ヘッダ出力なし)
[/E] データ追加フラグ (省略時は上書き)
[/V:nnnn] 処理経過表示敷居値 (省略時は非表示)
* /SQL > /S > /T の順で優先です.
/FIX = 固定長テキスト
/COMMA = カンマ区切り
/TAB = タブ区切り
/SPACE = 空白区切り
/DQ = 文字列項目をダブルクォーテーションで囲みます
/SQ = 文字列項目をシングルクォーテーションで囲みます
/Eパラメタ指定時はアンロード先ファイルが既に存在したらデータを追加します
* /SパラメタでSQLファイルを指定する場合、その中でシステム日付を使いたい場合
以下のパラメタを指定できます。
%SYSTIME% :システム時刻(HHNNSS)
%SYSDATE% :システム日付(YYYYMMDD)
%SYSDATE+n% :システム日付+n日の日付(YYYYMMDD)
%SYSDATE-n% :システム日付-n日の日付(YYYYMMDD)
戻り値
1:実行時初期化エラー
2:パラメタエラー
3:/Sパラメタに指定されたSQLファイルが存在しない
4:DBコンポーネント初期化エラー
5:SQLがSELECT文以外
6:ログインエラー、DBアクセスエラー
7:ファイルアクセスエラー
9:その他例外エラー
ex1) Ora2txtR /c:172.22.2.189@ORCL /u:usr01 /p:pwd01 /o:c:\work\test.txt /t:EMP /FIX
※ポート指定を省略した場合は1521が指定されたものとして扱う
ex2) Ora2txtR /c:ORASVR01:1522@ORCL /u:usr01 /p:pwd01 /o:c:\work\test.txt /t:EMP /FIX
【留意事項】
・利用に際して、事前のORACLEクライアントのインストールは不要です。
・/Sオプションで指定されるSQLファイルには1回のSELECT文が記述できます。
終端の";"は不要です。
・ROWID,BLOBなどテキストで出力するのが難しい(意味がない?)
データ型については処理しません。
対応データ型は、Char,VarChar2,Number,Date型のみです。
・DATE型の項目は "YYYY/MM/DD" 又は "YYYY/MM/DD hh:mm:ss.zzz" の形式で出力します。
固定長テキストモード時は YYYYMMDD 又は YYYYMMDDhhmmsszzz です。
・NUMBER(6,2)で定義されたデータに12.5という値が格納されている場合、
12.50 の形式で出力します。
固定長テキストモード時は +0012.50 です。
・テーブルは存在するがデータが無い場合、戻り値は0(正常)となります。
・固定長テキストモードで項目名は出力できません。
・処理経過表示敷居値については、/V:1000 とした場合、1000件毎に
「nnnn/xxxx件目を処理中...」のメッセージが表示されます。
最大値は、1000000です。
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
PostgreSQL専用アンローダ
PostgreSQLデータベースのテーブルから、レコードをテキストに抽出するためのツール
★コマンド使用法
PGS2TXT.exe /C:接続先(サーバIPアドレス 又は host名)
/U:ログインユーザ名
/P:ログインパスワード
{/SQL:"select sql文" /S:抽出SQLファイル名 | /T:テーブル名}
[ /O:アンロード先ファイル名 ] (省略時は標準出力)
[{/FIX | /COMMA | /TAB | /SPACE}] 区切り文字指定 (省略時は0x01)
[{/DQ | /SQ}] 文字セパレータ指定 (省略時はなし)
[/H] 項目名出力フラグ (省略時は項目ヘッダ出力なし)
[/E] データ追加フラグ (省略時は上書き)
[/V:nnnn] 処理経過表示敷居値 (省略時は非表示)
* /SQL > /S > /T の順で優先です.
/FIX = 固定長テキスト
/COMMA = カンマ区切り
/TAB = タブ区切り
/SPACE = 空白区切り
/DQ = 文字列項目をダブルクォーテーションで囲みます
/SQ = 文字列項目をシングルクォーテーションで囲みます
/Eパラメタ指定時はアンロード先ファイルが既に存在したらデータを追加します
* /SパラメタでSQLファイルを指定する場合、その中でシステム日付を使いたい場合
以下のパラメタを指定できます。
%SYSTIME% :システム時刻(HHNNSS)
%SYSDATE% :システム日付(YYYYMMDD)
%SYSDATE+n% :システム日付+n日の日付(YYYYMMDD)
%SYSDATE-n% :システム日付-n日の日付(YYYYMMDD)
戻り値
1:実行時初期化エラー
2:パラメタエラー
3:/Sパラメタに指定されたSQLファイルが存在しない
4:DBコンポーネント初期化エラー
5:SQLがSELECT文以外
6:ログインエラー、DBアクセスエラー
7:ファイルアクセスエラー
9:その他例外エラー
ex1) pgs2txt /c:10.10.1.1 /u:usr01 /p:pwd01 /o:c:\work\test.txt /t:EMP /FIX
ex2) pgs2txt /c:pgdbsv01 /u:usr01 /p:pwd01 /sql:"select * from MST001" /COMMA > .\dump.csv
【留意事項】
・/Sオプションで指定されるSQLファイルには1回のSELECT文が記述できます。
終端の";"は不要です。
・ROWID,BLOBなどテキストで出力するのが難しい(意味がない?)
データ型については処理しません。
対応データ型は、Char,VarChar2,Integer,Number,Date型のみです。
・DATE型の項目は "YYYY/MM/DD" 又は "YYYY/MM/DD hh:mm:ss.zzz" の形式で出力します。
固定長テキストモード時は YYYYMMDD 又は YYYYMMDDhhmmsszzz です。
・NUMBER(6,2)で定義されたデータに12.5という値が格納されている場合、
12.50 の形式で出力します。
固定長テキストモード時は +0012.50 です。
・テーブルは存在するがデータが無い場合、戻り値は0となります。
・固定長テキストモードで項目名は出力できません。
・処理経過表示敷居値については、/V:1000 とした場合、1000件毎に
「nnnn/xxxx件目を処理中...」のメッセージが表示されます。
最大値は、1000000です。
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。
一括文字コード変換
プログラムソースなどの複数のテキストファイルの文字コードを一括で変換するための省力化ツール
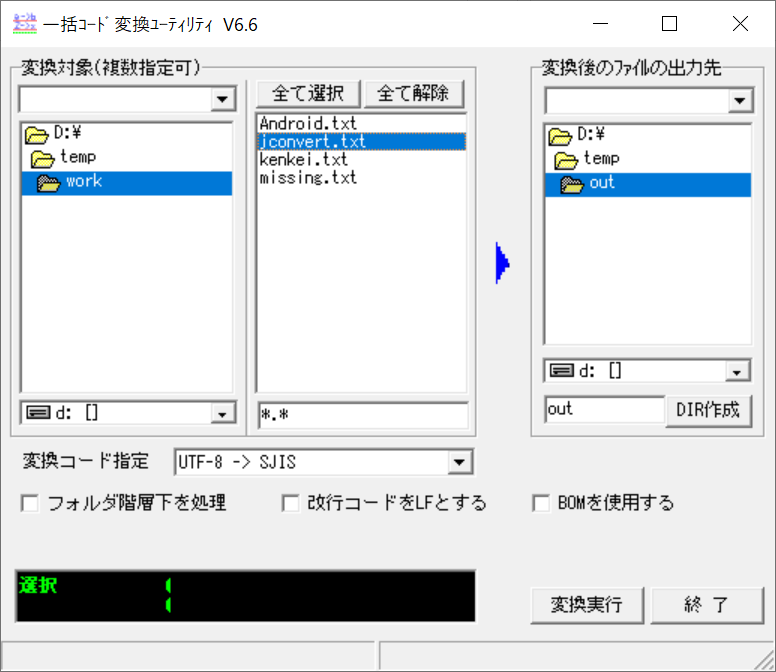
★GUI利用時の画面
・BATCHCNV.exeを起動し、変換元ファイル、変換結果出力先ディレクトリ と文字コードを指定してください。
★コマンド使用法
BATCHCNV.exe /I:C:\xxxx /O:C:\yyyy /FC:変換元コード /TC:変換先コード [オプションパラメタ]
/I:入力ファイル名
(ワイルドカード指定可.フォルダ名を指定した場合は\*.*と同じ)
/O:出力先フォルダ名
(入力ファイルと同じフォルダや、存在しない場合はエラーとします)
/FC:変換元コード{SJIS, EUC, UTF8, UNICD, JIS, EBC}
/TC:変換先コード{SJIS, EUC, UTF8, UNICD, JIS, EBC}
オプションパラメタ
/R (フォルダ階層下を処理する場合に指定)
/LF (変換先コードがSJIS,UTF8の場合で改行コードをLFのみにする場合に指定)
/SIO (変換先コードがJEFの場合でシフトコードを付加する場合に指定)
/CL (シフトコードを付加してレコード長が変更することを許可する場合に指定)
/LEN:nn (EBCDICから変換する際に入力レコード長を指定。省略時=80)
/TRIM (EBCDICから変換する際に出力レコードの終端空白を削除)
※フリーウェアとして一般的な免責事項などご理解の上、ご利用ください。